Apache Kafka盘点
一、基本术语
消息(Message)
Kafka中的数据单元称为消息,也被称为记录,可以把它看作数据库表中的某一行记录;
批次(Batch)
为了提高效率,消息会分批次写入Kafka,批次就代指的一组消息;
主题(Topic)
消息的种类为主题,可以说一个主题代表了一类消息。相当于对消息进行分类,主题就像数据库中的表;
分区(Partition)
主题可以被分为若干个分区,同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现kafka的伸缩性,单一主题中的分区有序,但是无法保证主题中的所有分区有序;
生产者(Producer)
向主题发布消息的客户端应用程序称为生产者,生产者用于持续不断的向某个主题发送消息;
消费者(Consumer)
订阅主题消息的客户端称为消费者,消费者用于处理生产者产生的消息;
消费者群组
由一个或者多个消费者组成的群体;
偏移量(Consumer Offset)
一种元数据,是一个不断递增的整数值,用来记录消费者发生重平衡的位置,以便用来恢复数据;
Broker
一个独立的Kafka服务器称为Broker,Broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存;
Broker集群
是集群的组成部分,有一个或者多个broker组成,每个集群都有一个broker同时充当集群控制器的角色(自动从集群的活跃成员中选举出来);
副本(Replica)
Kafka中消息备份叫副本,副本数量可以配置,并且Kafka定义了两类副本:领导者副本和追随者副本;前者对外提供服务,后者被动跟随;
重平衡(Rebalance)
消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalalce是Kafka消费者实现高可用的重要手段;
二、Kafka的特性(设计原则)
- 高吞吐、低延迟:收发消息快,每秒可以处理几十万条信息,最低延迟只有几毫秒;
- 高伸缩性:每个主题包含多个分区,主题中的分区可以分布在不同的主机中;
- 持久性、可靠性:允许数据持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka底层的数据存储是基于Zookeeper存储;
- 容错性:允许集群中的节点失败,某个节点宕机,Kafka集群能够正常工作;
- 高并发:支持数千个客户端同时读写;
三、使用场景
- 活动跟踪:例如跟踪用户行为;
- 消息传递:例如应用程序的发送通知,不需要关心消息格式,不需要关心数据如何发送;
- 度量指标:记录运营监控数据,包括收集各种分布式应用数据,生产各种操作的集中反馈,例如报警和报告;
- 日志记录:日志提交,例如可以把数据库更新发送到Kafka上,记录数据库更新时间,通过Kafka以统一接口服务的方式开放给各种consumer,例如Handoop,Hbase和Solr等;
- 流式处理:这个不清楚
- 限流削峰:某一时刻请求特别多,可以将请求写入Kafka中,避免直接请求后端程序导致服务崩溃;
四、消息队列
点对点模式
一个生产者对一个消费者,就称为点对点模式

发布订阅模式
多个生产者对多个消费者的情况,就成为发布订阅模式的消息队列

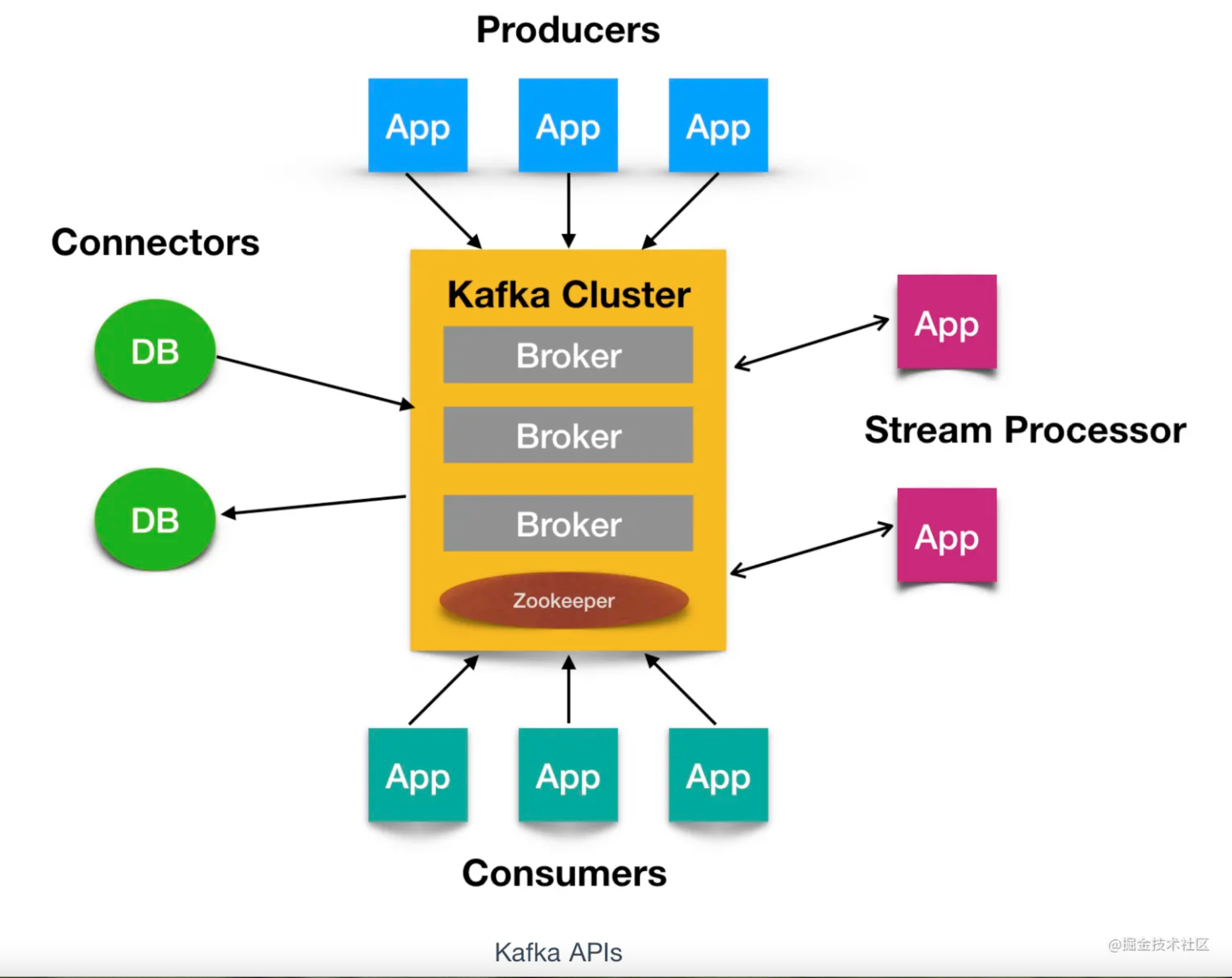
五、Kafka系统架构

一个典型的Kafka集群包括:
- 若干个Producer(可以是Web前端的Page View,服务器日志,系统CPU,Memory等);
- 若干个Broker(支持水平扩展,一般broker数量越多,集群吞吐率就越高);
- 若干个Consumer Group:
- Zookeeper集群(选举leader,以及在Consumer Group发生变化时进行rebalalce)
其中需要注意的是:Producer使用push模式推送消息,Consumer使用pull模式从broker订阅并消费消息;
六、核心API
有4个核心API,分别是:
- Producer API:允许应用程序向一个或者多个topics发送消息;
- Consumer API:允许应用程序向一个或多个topics并处理为其生成的记录流;
- Streams API:允许应用程序作为流处理器,从一个或多个主题中消费输入流并为其生成输出流,有效地将输入流转换为输出流;
- Connector API:允许构建和运行将Kafka主题连接到现有应用程序或数据系统的可用生产者和消费者;
七、Kafka为什么这么快
实现了零拷贝原理来快速移动数据,避免内核之间的切换。Kafka将数据记录分批发送,从生产者到文件系统(Kafka主题日志)到消费者,可以端到端的查看这些批次的数据;
总结下来就4个点:
- 顺序读写
- 零拷贝
- 消息压缩
- 分批发送
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!