Redis盘点梳理
Redis数据类型
基础数据类型
- 字符串 String
- 列表 List
- 哈希 Hash
- 集合 Set
- 有序集合 Zset
- Bitmaps
- HyperLogLogs
- GEO
底层数据类型
- 简单动态数组 SDS
- 链表
- 字典
- 跳跃链表
- 整数集合
- 压缩列表
- 对象

ziplist压缩列表可以作为Zset、Hash、List三种数据类型的底层实现,其中Zset使用到了跳跃链表;
SDS (Simple Dynamic String)
什么是SDS
SDS是Redis中String类型数据的数据结构,Redis作者没有使用C字符串,而是自己设计了一种数据结构来存储字符串数据;
1 | |
贴个图来展示SDS的数据结构:
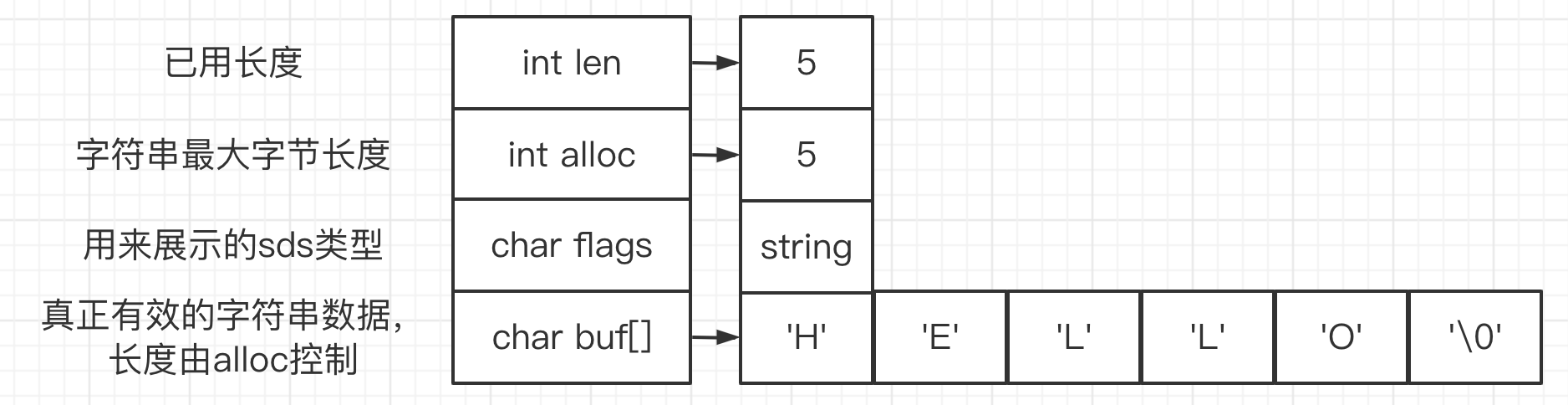
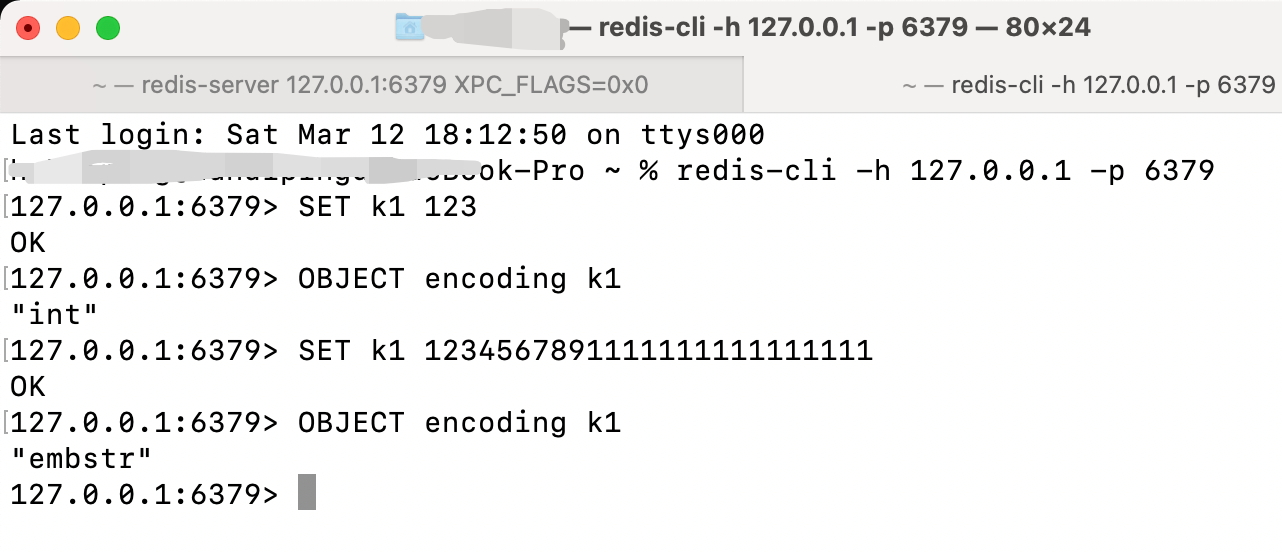
这里说一下flags,在Redis中当你给String赋值不同类型的字符,它所展示的数据类型是不同的;
SDS和C字符串的区别
- 获取字符串的长度:O(1),C字符串是O(N);
- 缓冲区溢出:API是安全的,不会造成缓冲区溢出,C字符串会;
- 惰性分配:修改N次长度最多需要进行N次内存重分配;而C字符串是必然会进行N次内存分配;
- 数据存储:C字符串只能存储文本数据,SDS既可以存储文本也可以存储二进制数据;
SDS的优点
- 常数获取字符串的复杂度,无需遍历;
- 杜绝缓冲区溢出;
- 减少修改字符串修改分配内存的次数;
- 二进制安全;
- 兼容部分C字符串;
链表
链表的数据结构在我们日常的使用中已经非常常见了,所以这里我稍微介绍一点Redis中所不同的概念:
1 | |

可以总结出Redis的链表存在下列特点:
- 存在prev和next指针,因此获取某个节点的前置和后置节点时间复杂度都是O(1);
- 表头的prev指针和表尾的next指针都指向NULL,所以它一定是无环结构;
- 存在表头和表尾指针,因此获取链表的头节点和尾节点时间复杂度都是O(1);
- 自带链表长度的计数器,获取链表长度的时间复杂度也是O(1);
- 使用void*保存节点值,所以可以存储不同类型的数据;
基于上述特点,我们可以发现链表广泛使用发布订阅、慢查询、监视器以及列表键。(为什么呢?)
因为上述数据结构采用了空间换时间的概念,所以在数据量大的情况下使用链表能够很好的提高性能;而在数据量较小的时候,这种浪费就显得没有必要了,一般会使用压缩链表来实现;
字典
字典是一种用于保存键值对的抽象数据结构;字典中每个键都是独一无二的,程序可以在字典中根据键值查找与之相关联的值;同样C语言没有内置这种数据结构,Redis自己实现了字典;
字典底层的数据结构
字典使用了哈希表作为底层实现,一个哈希表可以有多个哈希节点,每个哈希表节点保存了字典的键值对;
Redis缓存
Redis缓存雪崩
成因
同一时间大批量数据失效导致Redis变成不存在,请求压力全部落到数据源导致系统压力增加;
解决方案
分布式部署,设置热点数据永不过期,有更新操作再刷新Redis缓存,或者是给Redis缓存key失效时间加随机值
Redis缓存击穿
成因
某个热点数据失效,大量针对这个数据的请求会穿透缓存到数据库
解决方案
可以使用互斥锁更新,保证同一个进程中针对同一个数据不会并发请求到 DB,减小 DB 压力。
使用随机退避方式,失效时随机 sleep 一个很短的时间,再次查询,如果失败再执行更新。
针对多个热点 key 同时失效的问题,可以在缓存时使用固定时间加上一个小的随机数,避免大量热点 key 同一时刻失效。
Redis缓存穿透
成因
缓存和数据库中都没有的数据,用户不断发起请求,导致数据库的压力增大,从而搞垮系统;一般出现这种情况是因为没有对参数做校验导致。
解决方案
对于不存在的用户,在缓存中保存一个空对象标记,防止相同ID再次访问DB;但是这个方法不能解决问题;
使用布隆过滤器,特点是数据的唯一性校验,存在为true,不存在为false,非常适合解决这些问题;
Redis持久化操作
RDB:RDB 持久化机制,是对 Redis 中的数据执行周期性的持久化。
AOF:AOF 机制对每条写入命令作为日志,以 append-only 的模式写入一个日志文件中,因为这个模式是只追加的方式,所以没有任何磁盘寻址的开销,所以很快,有点像Mysql中的binlog。
RDB
AOF
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!